Why reputation? Reputation and reproducibility are somewhat related but clearly distinct concepts. In my field (I guess?) of molecular biology, I think that reputation and reproducibility are particularly strongly correlated because the nature of the field is such that perceived reproducibility is heavily tied to the large number of judgement calls you have make in the course of your research. As such, perhaps reputation has evolved as the best way to measure reproducibility in this area.
I think that this stands in stark contrast with the more common diagnosis one sees these days for the problem of irreproducibility, which is that it's all down to statistical innumeracy. Every so often, I’ll see tweets like this (names removed unless claimed by owner):



The implication here is that the problem with all this “cell” biology is that the Ns are so low as to render the results statistically meaningless. The implicit solution to the problem is then “Isn’t data cheap now? Just get more data! It’s all in the analysis, all we need to do is make that reproducible!” Well, if you think that github accounts, pre-registered studies and iPython notebooks will magically solve the reproducibility problem, think again. Better statistical and analysis management practices are of course good, but the excessive focus on these solutions to me ignores the bigger point, which is that, especially in molecular and cellular biology, good judgement about your data and experiments trumps all. (I do find it worrying that statistics has somehow evolved to the point of absolving ourselves of the responsibility for the scientific inferences we make ("But look at the p-value!"). I think this statistical primacy is perhaps part of an bigger—and in my opinion, ill-considered—attempt to systematize and industrialize scientific reasoning, but that’s another discussion.)
Here’s a good example from the (infamous?) study claiming to show that aspartame induces cancer. (I looked this over a while ago given my recently acquired Coke Zero habit. Don’t judge.) Here’s a table summarizing their results:
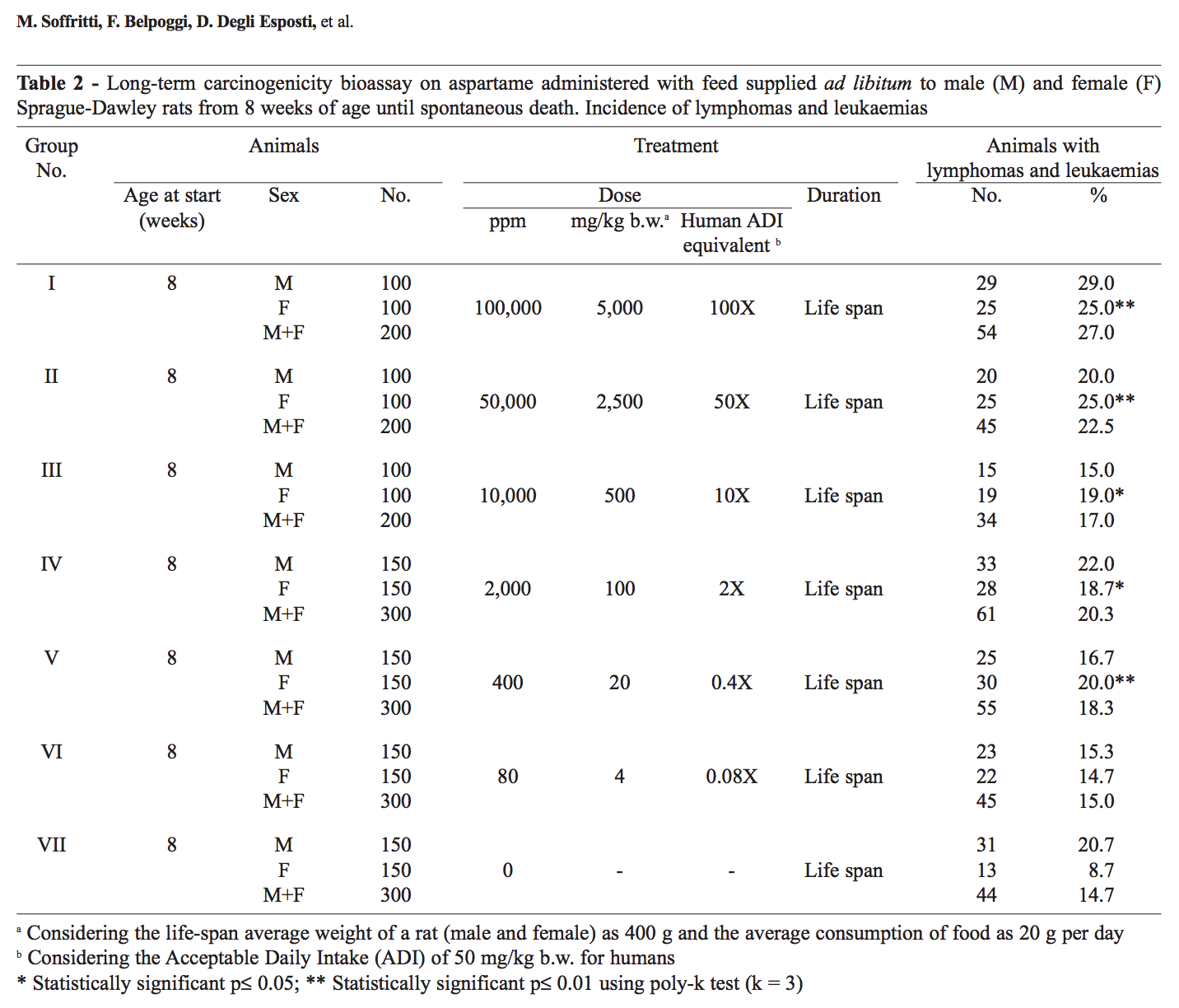
The authors claim that this shows an effect of increased lymphomas and leukemias in the female rats through the entire dose range of aspartame. And while I haven’t done the stats myself, looking at the numbers, the claim seems statistically valid. But the whole thing really hinges on the one control datapoint for the female rats, which is (seemingly strangely) low compared to virtually everything else. If that number was, say, 17% instead of 8%, I’m guessing essentially all the statistical significance would go away. Is this junk science? Well, I think so, and the FDA agrees. But I would fully agree that this is a judgement call, and in a vacuum would require further study—in particular, to me, it looks like there is some overall increase in cancers in these rats at very high doses, and while it is not statistically significant in their particular statistical treatment, my feeling is that there is something there, although probably just a non-specific effect arising from the crazy high doses they used.
Hey, you might say, that’s not science! Discarding data points because they “seem off” and pulling out statistically weak “trends” for further analysis? Well, whatever, in my experience, that’s how a lot of real (and reproducible) science gets done.
Now, it would be perfectly reasonable of you to disagree with me. After all, in the absence of further data, my inklings are nothing more than an opinion. And in this case, at least we can argue about the data as it is presented. In most papers in molecular biology, you don’t even get to see the data from all experiments they didn’t report for whatever reason. The selective reporting of experiments sounds terrible, and is probably responsible for at least some amount of junky science, but here’s the thing: I think molecular biology would be uninterpretable without it. So many experiments fail or give weird results for so many different reasons, and reporting them all would leave an endless maze that would be impossible to navigate sensibly. (I think this is a consequence of studying complex systems with relatively imprecise—and largely uncalibrated—experimental tools.) Of course, such a system is ripe for abuse, because anyone can easily leave out a key control that doesn’t go their way under the guise of “the cells looked funny that day”, but then again, there are days where the cells really do look funny. So basically, in the end, you are stuck with trust: you have to trust that the person you’re listening to made the right decisions, that they checked all the boxes that you didn’t even know existed, and that they exhibited sound judgement. How do you know what work to follow up on? In a vacuum, hard to say, but that’s where reputation comes in. And when it comes to reputation, I think there’s value in playing the long game.
Reputation comes in a couple different forms. One is public reputation. This is the one you get from talks you give and the papers you publish, and it can suffer from hype and sloppiness. People do still read papers and listen to talks (well, at least sometimes), and eventually they will notice if you cut corners and oversell your claims. Not much to say about this except that one way to get a good public reputation is to, well, do good science! Another important thing is to just be honest. Own up to the limitations of your work, and I’ve found that people will actually respect you more. It’s pretty easy to sniff out someone who’s being disingenuous (as the lawyerly answers from Elizabeth Holmes have shown), and I think people will actually respect you more if you just straight up say what you really think. Plus, it makes people think you’re smart if you show you’ve already thought about all the various problems.
Far more murky is the large gray zone of private reputation, which encompasses all the trust in the work that you don’t see publicly. This is going out to dinner with a colleague and hearing “Oh yeah, so-and-so is really solid”… or “That person did the same experiment 40 times in grad school to get that one result” or “Oh yeah, well, I don’t believe a single word out of that person’s mouth.” All of which I have heard, and don’t let me forget my personal favorite “Mr. Artifact bogus BS guy”. Are these just meaningless rumors? Sometimes, but mostly not. What has been surprising to me is how much signal there is in this reputational gossip relative to noise—when I hear about someone with a shady reputation, I will often hear very similar things independently from multiple sources.
I think this is (rightly) because most scientists know that spreading science gossip about people is generally something to be done with great care (if at all). Nevertheless, I think it serves a very important purpose, because there’s a lot of reputational information that is just hard to share publicly. Many reasons for this, one of them being that the burden of proof for calling someone out publicly is very high, the potential for negative fallout is large, and you can easily develop your own now-very-public reputation for being a bitter, combative pain in the ass. A world in which all scientists called each other out publicly on everything would probably be non-functional.
Of course, this must all be balanced against the very significant negatives to scientific gossip. It is entirely possible that someone could be unfairly smeared in this way, although honestly, I’m not sure how many instances of this I’ve really seen. (I do know of one case in which one scientist supposedly started a whisper campaign against another scientist about their normalization method or something suitably petty, although I have to say the concerns seemed valid to me.)
So how much gossip should we spread? For me, that completely depends on the context. With close friends, well, that’s part of the fun! :) With other folks, I’m of course far more restrained, and I try to stick to what I know firsthand, although it’s impossible to give a straight up rule given the number of factors to weigh. Are they asking for an evaluation of a potential collaborator? Are we discussing a result that they are planning to follow up on in the lab, thus potentially harming a trainee? Will they even care what I say either way? An interesting special case is trainees in the lab. I think they actually stand to benefit greatly from this informal reputational chatter. Not only do they learn who to avoid, but even just knowing the fact that not everyone in science can be trusted is a valuable lesson.
Which leads to another important problem with private reputations: if they are private, what about all the other people who could benefit from that knowledge but don’t have access to it? This failure can manifest in a variety of ways. For people with less access to the scientific establishment (smaller or poorer countries, e.g.), you basically just have to take the literature at face value. The same can be true even within the scientific establishment; for example, in interdisciplinary work, you’ll often have one community that doesn’t know the gossip of another (lots of examples where I’ll meet someone who talks about a whole bogus subfield without realizing it’s bogus). And sometimes you just don’t get wind in time. The damage in terms of time wasted is real. I remember a time when our group was following up a cool-seeming result that ended up being bogus as far as we could tell, and I met a colleague at a conference, told her about it, and she said they saw the same thing. Now two people know, and perhaps the handful of other people that I’ve mentioned this to. That doesn’t seem right.
At this point, I often wonder about a related issue: do these private reputations even matter? I know plenty of scientists with widely-acknowledged bad reputations who are very successful. Why doesn’t it stick? Part of it is that our review systems for papers and grants just don’t accommodate this sort of information. How do you give a rational-sounding review that says “I just don’t believe this”? Some people do give those sorts of reviews, but come across as, again, bitter and combative, so most don’t. Not sure what to do about this problem. In the specific case of publishing papers, I often wonder why journal editors don’t get wind of these issues. Perhaps they just are in the wrong circles? Or maybe there are unspoken union rules about ratting people out to editors? Or maybe it’s just really hard not to send a paper to review if it looks strong on the face of it, and at that point, it’s really hard for reviewers to do anything about it. It is possible that preprints and more public discussion may help with this? Of course, then people would actually have to read each other’s papers…
That said, while the downsides of a bad private reputation may not materialize as often as we feel they should, the good news is that I think the benefits to a good private reputation can be great. If people think you do good, solid work, I think that people will support you even if you’re not always publishing flashy papers and so forth. It’s a legitimate path to success in science, and don’t let the doom and gloomers and quit-lit types tell you otherwise. How to develop and maintain a good private reputation? Well, I think it’s largely the same as maintaining a good public one: do good science and don’t be a jerk. The main difference is that you have to do these things ALL THE TIME. There is no break. Your trainees and mentors will talk. Your colleagues will talk. It’s what you do on a daily basis that will ensure that they all have good things to say about you.
(Side point… I often hear that “Well, in industry, we are held to a different standard, we need things to actually work, unlike in academia.” Maybe. Another blog post on this soon, but I’m not convinced industry is any better than academia in this regard.)
Anyway, in the end, I think that molecular biology is the sort of field in which scientific reputation will remain an integral part of how we assess our science, for better or for worse. Perhaps we should develop a more public culture of calling people out like in physics, but I’m not sure that would necessarily work very well, and I think the hostile nature of discourse in that field contributes to a lack of diversity. Perhaps the ultimate analysis of whether to spread gossip or do something gossip-worthy is just based on what it takes for you to get a good night’s sleep.
